Enable CPU Sharing in ACRN¶
Introduction¶
The goal of CPU Sharing is to fully utilize the physical CPU resource to
support more virtual machines. Currently, ACRN only supports 1 to 1
mapping mode between virtual CPUs (vCPUs) and physical CPUs (pCPUs).
Because of the lack of CPU sharing ability, the number of VMs is
limited. To support CPU Sharing, we have introduced a scheduling
framework and implemented two simple small scheduling algorithms to
satisfy embedded device requirements. Note that, CPU Sharing is not
available for VMs with local APIC passthrough (--lapic_pt option).
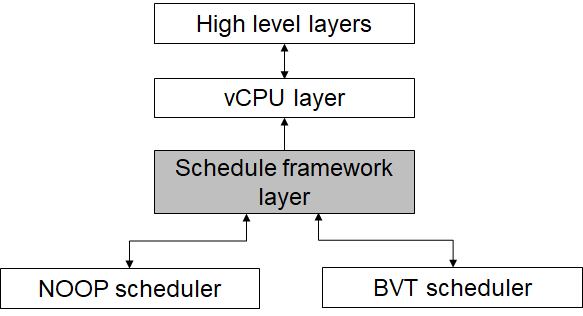
Scheduling Framework¶
To satisfy the modularization design concept, the scheduling framework layer isolates the vCPU layer and scheduler algorithm. It does not have a vCPU concept so it is only aware of the thread object instance. The thread object state machine is maintained in the framework. The framework abstracts the scheduler algorithm object, so this architecture can easily extend to new scheduler algorithms.
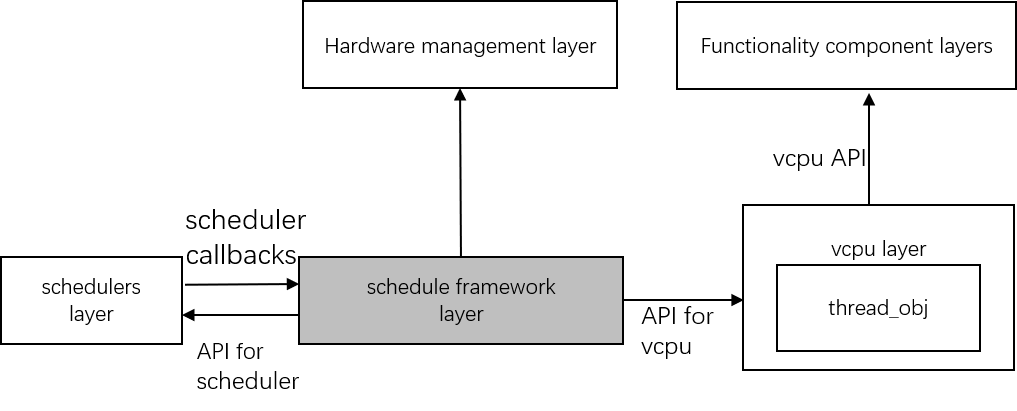
The below diagram shows that the vCPU layer invokes APIs provided by
scheduling framework for vCPU scheduling. The scheduling framework also
provides some APIs for schedulers. The scheduler mainly implements some
callbacks in an acrn_scheduler instance for scheduling framework.
Scheduling initialization is invoked in the hardware management layer.
CPU Affinity¶
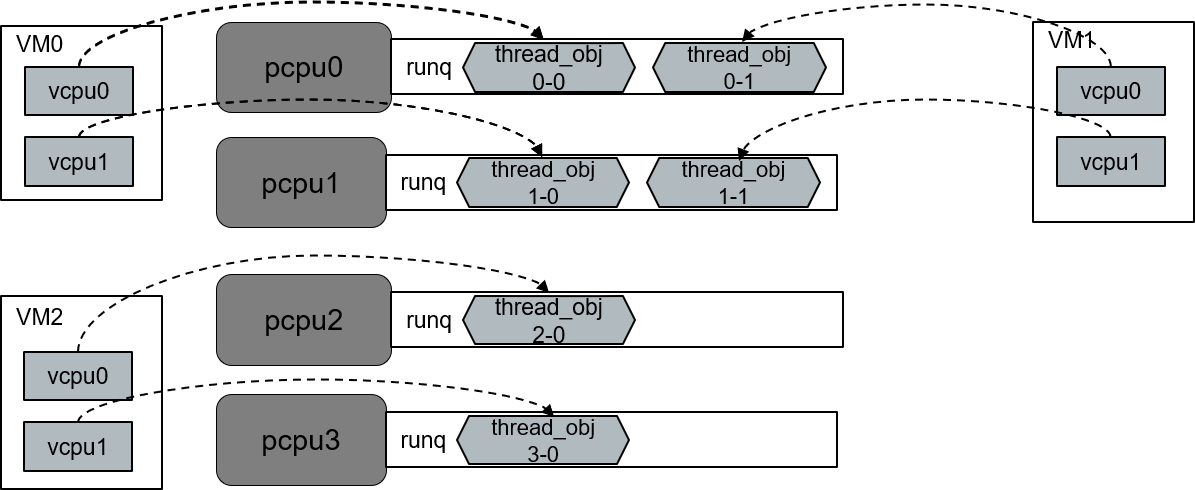
Currently, we do not support vCPU migration; the assignment of vCPU mapping to pCPU is fixed at the time the VM is launched. The statically configured cpu_affinity in the VM configuration defines a superset of pCPUs that the VM is allowed to run on. One bit in this bitmap indicates that one pCPU could be assigned to this VM, and the bit number is the pCPU ID. A pre-launched VM is launched on exactly the number of pCPUs assigned in this bitmap. The vCPU to pCPU mapping is implicitly indicated: vCPU0 maps to the pCPU with lowest pCPU ID, vCPU1 maps to the second lowest pCPU ID, and so on.
For post-launched VMs, acrn-dm could choose to launch a subset of pCPUs that
are defined in cpu_affinity by specifying the assigned pCPUs
(--cpu_affinity option). But it can’t assign any pCPUs that are not
included in the VM’s cpu_affinity.
Here is an example for affinity:
VM0: 2 vCPUs, pinned to pCPU0 and pCPU1
VM1: 2 vCPUs, pinned to pCPU0 and pCPU1
VM2: 2 vCPUs, pinned to pCPU2 and pCPU3
Thread Object State¶
The thread object contains three states: RUNNING, RUNNABLE, and BLOCKED.
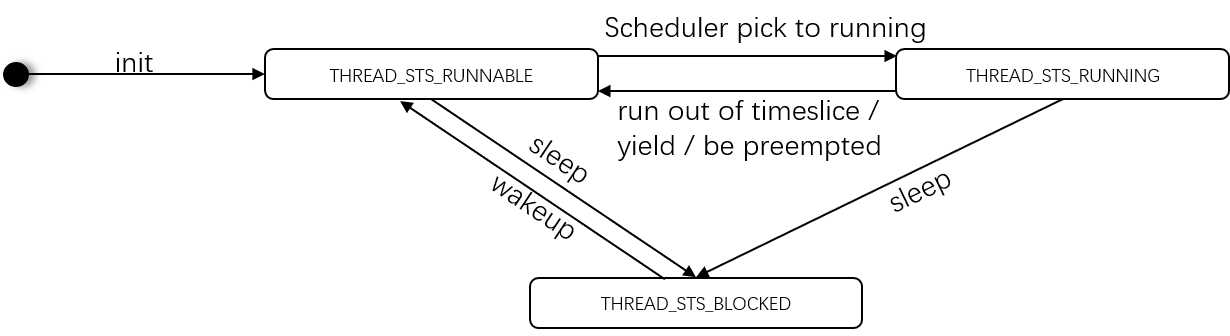
After a new vCPU is created, the corresponding thread object is initiated. The vCPU layer invokes a wakeup operation. After wakeup, the state for the new thread object is set to RUNNABLE, and then follows its algorithm to determine whether or not to preempt the current running thread object. If yes, it turns to the RUNNING state. In RUNNING state, the thread object may turn back to the RUNNABLE state when it runs out of its timeslice, or it might yield the pCPU by itself, or be preempted. The thread object under RUNNING state may trigger sleep to transfer to BLOCKED state.
Scheduler¶
The below block diagram shows the basic concept for the scheduler. There are two kinds of schedulers in the diagram: NOOP (No-Operation) scheduler and BVT (Borrowed Virtual Time) scheduler.
No-Operation scheduler:
The NOOP (No-operation) scheduler has the same policy as the original 1-1 mapping previously used; every pCPU can run only two thread objects: one is the idle thread, and another is the thread of the assigned vCPU. With this scheduler, vCPU works in Work-Conserving mode, which always tries to keep resources busy, and will run once it is ready. The idle thread can run when the vCPU thread is blocked.
Borrowed Virtual Time scheduler:
BVT (Borrowed Virtual time) is a virtual time based scheduling algorithm, it dispatches the runnable thread with the earliest effective virtual time.
TODO: BVT scheduler will be built on top of prioritized scheduling mechanism, i.e. higher priority threads get scheduled first, and same priority tasks are scheduled per BVT.
Virtual time: The thread with the earliest effective virtual time (EVT) is dispatched first.
Warp: a latency-sensitive thread is allowed to warp back in virtual time to make it appear earlier. It borrows virtual time from its future CPU allocation and thus does not disrupt long-term CPU sharing
MCU: minimum charging unit, the scheduler account for running time in units of MCU.
Weighted fair sharing: each runnable thread receives a share of the processor in proportion to its weight over a scheduling window of some number of MCU.
C: context switch allowance. Real time by which the current thread is allowed to advance beyond another runnable thread with equal claim on the CPU. C is similar to the quantum in conventional timesharing.
Scheduler configuration
The scheduler used at runtime is defined in the scenario XML file via the
hv.FEATURES.SCHEDULERoption. The default scheduler is SCHED_BVT. Use the ACRN configurator tool if you want to change this scenario option value.
The default scheduler is SCHED_BVT.
The cpu_affinity could be configured by one of these approaches:
Without
cpu_affinityoption in acrn-dm. This launches the user VM on all the pCPUs that are included in the statically configured cpu_affinity.With
cpu_affinityoption in acrn-dm. This launches the user VM on a subset of the configured cpu_affinity pCPUs.
For example, assign physical CPUs 0 and 1 to this VM:
--cpu_affinity 0,1
Example¶
Use the following settings to support this configuration in the industry scenario:
pCPU0 |
pCPU1 |
pCPU2 |
pCPU3 |
|---|---|---|---|
Service VM + WaaG |
RT Linux |
||
offline pcpu2-3 in Service VM.
launch guests.
launch WaaG with “–cpu_affinity 0,1”
launch RT with “–cpu_affinity 2,3”
After you start all VMs, check the CPU affinities from the Hypervisor
console with the vcpu_list command:
ACRN:\>vcpu_list
VM ID PCPU ID VCPU ID VCPU ROLE VCPU STATE THREAD STATE
===== ======= ======= ========= ========== ==========
0 0 0 PRIMARY Running RUNNING
0 1 1 SECONDARY Running RUNNING
1 0 0 PRIMARY Running RUNNABLE
1 1 1 SECONDARY Running BLOCKED
2 2 0 PRIMARY Running RUNNING
2 3 1 SECONDARY Running RUNNING
Note: the THREAD STATE are instant states, they will change at any time.